Day 0 - Primer
flag
In my personal opinion, python in Houdini has been one of the most rewarding things to learn. In Houdini, python is a very open ended and well documented, and allows you to customize and enhance your daily experience in the software.
The aim of this advent challenge is to take anyone from nothing to comfortable building tools to aid your experience.
If you are interesting in following this, I suggest downloading this template package, and following the instructions on getting installed.
There are no rules, except to join the Discord, ask questions, and have fun!
Each day will ideally have a "Extra Info" section with some useful things at a similar level of difficulty to the days info. Read these and try and implement them where you see fit.
Prompt: Plan out some common pain points or workflow slowdowns to optimize in your personal pipeline.
Installing the template package
Download the template package from here, and place it somewhere in your assets folder. Open the TDP.json. Inside it, it will look like this:
{
"env": [
{
"TDP": "path/to/folder"
}
],
"path": "$TDP"
}Replace path/to/folder with the actual path to the TDP folder, for example: D:/Assets/TDP, and then copy this .json file to your Houdini preference folder (houdini20.5/packages)
For this template, I am using the name Twelve Days of Python, so TDP. We set the environment variable up with this name, and in most cases, I will prefix any file names with this, this ensures all the references to files down the line wont be ambiguous. eg. utils.py is probably going to exist somewhere, so calling it TDPUtils.py has as much higher chance of being unique.
Verify the install by opening Houdini, pressing CTRL+S and typing $TDP in the path, and check if it directs you to the correct folder.
Code Editor
There are a bit more words here on how and why to set up your code editor to autocomplete the Houdini bits of your code.

While I don't claim to be the ideal teacher for this stuff, I have found myself looking for things and coming up short. Information is spread wide online, and once you know what to search for, things start popping up and searching becomes easier.
This is why I think arguably the most important thing to hone is your understanding of what you need to do. The thing I love most about this is that the code literally exists. There are functions for everything, and learning how to map more generic concepts into your specific use-case is a really powerful tool. Before that, we need to start at the beginning. (Something like this)
The reason we are using the package provided
Quick reminder to download/redownload the package as you read this, as I may have added something since the first time you saw it.
Houdini has many places to store custom code: hou.session, shelf scripts, HDAs, python nodes, python panels, startup scripts, etc. Most of these are embedded in Houdini, which makes version control tough, and you may even find yourself ended up with a busted shelf where all of your tools are now blank (it's happened to me!).
We use this custom package to solve a few problems: Being able to share your files, being able to enable/disable things, to manage version control, and above all else, just to edit in your favorite code editor.
You don't have to do this, but I urge you to follow along and keep things neat and tidy.
Useful concepts:
Functions: A function in Python is a reusable block of code that performs a specific task. In the context of Houdini, functions are crucial for creating custom tools, managing node operations, and automating workflows. We will use these to bundle up our code into high performing chunks that we can adapt later down the line.
Function Arguments: Function arguments in Python allow you to pass different values to functions, and control the flow of code in the function. We can use this to customize node creation, parameter manipulation, and other operations.
Node Types: The way we know nodes might be something like "Attribute Noise", but behind the scenes, these nodes have what is called a "type name", which is what you see when you MMB on a node at the top. Attribute Noise ends up being "attribnoise::2:0". The node info shelf tool in the package can help you see these names.
What we are going to do
We will start of simple with the basics on how to construct a function and how to pass arguments to it, this will allow us to create small wrappers that house our more complex code. This is useful for as a framework pass code between our Houdini and our code that lives in our package folder. This is also nice as at allows us to wrap commonly used workflows in a function and reuse it throughout our code.
We will create a system to make output nulls for our selected nodes, and learn how to loop through multiple nodes, this will help us understand the fundamentals of working with nodes and their paths, and how we can define nodes explicitly or programatically.
Once we know that, we will go over how to create new nodes, store them in our code and make connections to them and other nodes, as this is the foundation for all of our usual automation tasks. We will learn about node types, and how to use the docs to understand more about our nodes.
Further down the line, we will go into the more advanced things, like adding scripts the menus, creating UI prompts for options, reading attributes from our geometry, and even making our own custom python panels for menus and popups.
If you got this far, you may be wondering: "Where the hell is the python?" It's coming, but first, we need to learn to understand.
That being said, if you want to do your first ever python in Houdini: Open Houdini, click "window" at the top, and open the python shell. Paste this in:
import hou
hou.ui.displayMessage("Whoaaaaa!")
container = hou.node("/obj").createNode("geo", "whoaaaaa")
font = container.createNode("font")
font.parm("text").set("12 Days of Python")
a = font.createOutputNode("null", "OUT")
a.setColor(hou.Color((1.0, 0.0, 0.0)))
b = a.createOutputNode("null", "OUT")
b.setColor(hou.Color((0.0, 1.0, 0.0)))
c = b.createOutputNode("null", "OUT")
c.setColor(hou.Color((0.0, 0.0, 1.0)))
hou.ui.displayMessage("Let's get started!")The simplest thing you can do is make Houdini talk back to you. The first thing we are going to do, is go up to the shelf tab for our package. You will see tool already called "Reload Module", as well as one called "Node Info". Don’t mind these for now, and right click in the empty space and create a new shelf tool.
Shelf tools can store and run code just the way they are, but it’s good practice to store the code in a file in your package, import it and run it from the shelf tool.
Change the path at the top to the location of the shelf tool.
This is very important. It ensures that the script is stored in the package folder too and accessible by anyone who has the package installed.
Let’s come up with a good name for our script, for this example, let’s call it TDPUtils. In the code block, we write:
import TDPUtils
TDPUtils.greet()You may be wondering what this means, where is TDPUtils and where is it being imported from?
Well, let’s open our package folder in our favorite code editor, and go to /scripts/python and create our file called TDPUtils.py.
You may have noticed, in our shelf tool, we used TDPUtils.greet(), this is when we make the greet function in our file:
def greet():
print("Hey there!")
Now, a caveat of Houdini, all of these files are loaded when it starts, so clicking our shelf tool will fail to pull our changes. Restart Houdini before the next step.
Click our shelf tool, and we should see a small window pop up that says… "Hey there!".
Congratulations, you have made your first shelf tool!
Click here for some notes about reloading these files so you can avoid restarting Houdini every time you make a change.
Reloading the package
The "Reload Module" shelf tool acts as a button that will refresh all the loaded python files in the module. This is crucial for ensuring Houdini is reading the updated files you have been editing in your code editor. After any changes in your files, you can click this button and all your changes will be reloaded into Houdini.
Using arguments
Now that you have made your first function, one might think of how and where these could be used, and often times a bit of modularity is required too. Let's take the example of our greet function: How can we add more functionality? Running with our greet function, we can adjust the function to accept an argument. Let's call it first_time:
def greet(first_time):
if first_time:
print("Hey there!")
else:
print("Hello again!")We added a condition to check if the first time argument is True, and if we reload and run now, we will get an error. We need to adjust our shelf tool to call the function with the argument:
import TDPUtils
TDPUtils.greet(True)Now, if we pass True, it replies "Hey there!", and if we pass False, we get "Hello again!".
This is a simple example, but the concept of setting up logic and passing information from Houdini to our script is the foundation of everything we can do with Python in Houdini.
Prompt: Create a function that takes the currently selected nodes, and prints each of them to the console.
Extra Info
When we create our function, we can set it up to accept an optional argument, where we set a default value for the argument, and if the argument is omitted, it will use that value:
def greet(first_time=True):
if first_time:
print("Hey there!")
else:
print("Hello again!")Now if we call greet() without the argument, we print "Hey there!".
If you did the prompt for Day 2, you may have ended up with a function that looks something like this:
import hou
def print_nodes():
nodes = hou.selectedNodes()
print(nodes)
# or maybe
for node in nodes:
print(nodes)The second bit, looping through our nodes is also one of the bread and butter workflows when doing simpler stuff, especially in the start, where most of our interests lie in speeding up tedious workflows.
Lets's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes.
Nodes
As showcased above, getting a node can be done with a few methods, the easiest of which is going to be the selected nodes. This is also common, as often you will want to operate on these. If you did the above, you would see it prints some gibberish as well as some recognizable info, such as the node name. The correct thing to do now would be to go and read through the docs page for hou.OpNode and hou.Node (the difference is explained in todays extra info).
For this exercise, we will make a simple script to create an output null for any node we have selected. To start, we can work in our TDPUtils.py file, and create a new function. I will call it create_output_null. It's good to be as verbose as possible with naming, as things can get complex fast, and being vague doesn't help anybody.
import hou
def greet(first_time=True):
if first_time:
print("Hey there!")
else:
print("Hello again!")
def create_output_null():
passWe left pass there, which essentially means "do nothing". Now that we have this ready, we can quickly make a new shelf tool, and make it call our function:
import TDPUtils
TDUtils.create_output_null()From this point on, the creating of shelf tools won't be explained again, so save this area if its something you need to come back to.
Now, we can go back to our script, let's walk through creating our function.
import hou
def create_output_null():
node = hou.selectedNodes()[0]
print(type(node))Here we use [0] to get the first selected node (more on this later, don't worry). Here, we print type(node). This will give us the type of the data stored in the variable. So now that we have our node, and the print statement has confirmed our node type to be hou.SopNode (Just a variation of hou.OpNode) it's a good time to go and read the docs page for hou.OpNode and see what functions are available to us.
We will be using .createOutputNode(), which has the required arguments listed. Remember how we create optional arguments in yesterday's code? Take note of which arguments are optional in this case. The only required one, is node_type_name. In our case, we want to create a null, so create a null manually, and click the shelf tool "Node Info". This will print the node info for us to use, specifically "Type Name: null", so we can build our script now:
import hou
def create_output_null():
node = hou.selectedNodes()[0]
node.createOutputNode("null")Now, if we select a node and run this, it will create an null, and connect it to the output of our node. This works well for a single node, which we have selected with our [0] bit, but now the next step is to do it for all of our nodes.
Let's first adjust our script and run it:
import hou
def create_output_null():
nodes = hou.selectedNodes() # We get our selected items
print(type(nodes))It is crucial to know that what we get back here is: <class 'tuple'>. More reading on this in the extra info, as well as here. The bottom line is that this is a list of nodes, and in python, we can loop through a list/tuple very easily with by writing for item in list_of_items. Let's modify our script to run through each item:
import hou
def create_output_null():
nodes = hou.selectedNodes() # We get our selected items
for node in nodes:
node.createOutputNode("null")Now, when we select a bunch of nodes, and run the script, we get a null for each node. Knowing that inside of the loop we are operating on each node one by one, we can go a step further and set the name of the null to the name of our selected node:
import hou
def create_output_null():
nodes = hou.selectedNodes() # We get our selected items
for node in nodes:
new_name = "OUT_" + node.name()
output = node.createOutputNode("null", node_name=new_name)We pass node_name explicitly here, by writing node_name=new_name, but technically as its the second argument, we can just write node.createOutputNode("null", new_name), but it is good practice to keep track of what arguments you are passing to the functions
Here, we create a new_name variable to store the name, as well as store the null as output. You will use this if you do the prompt for today.
Now, we have a clean null named "Out_" for each of our nodes. Congratulations, you have connected some nodes! Bind this shelf tool to a hotkey and you have a useful workflow enhancer.
Some more info on creating nodes: createOutputNode is only one way to make a node, there are many more hidden in the docs. node.createNode() is a bread an butter function for creating a node, but it doesn't handle making connections for us like we had before. As always, the docs are contain a wealth of information, but I will outline a quick way to create a node and connect it to our selected node:
import hou
def create_output_null():
node = hou.selectedNodes()[0] # we are only getting the first node
new_name = "OUT_" + node.name()A really important thing here, is that when you create a node, it exists inside its parent. For example. a simple Box node may have a path like /obj/geo1/box1. The node's parent is geo1, and we use this to create the node. An analogy: In a book you have page and on the page you have a word. Logically, if life were Python, you would call page.createWord() rather than word.createWord() as words don't "contain" other words.
import hou
def create_output_null():
node = hou.selectedNodes()[0] # we are only getting the first node
new_name = "OUT_" + node.name()
parent = node.parent() # get the parent node
null = parent.createNode("null", node_name=new_name)Now, the node is created, but it is not connected. There are helper functions for setting the first input, but for this example, I will use the long winded approach to explain it:
import hou
def create_output_null():
node = hou.selectedNodes()[0] # we are only getting the first node
new_name = "OUT_" + node.name()
parent = node.parent() # get the parent node
null = parent.createNode("null", node_name=new_name)
null.setInput(0, node)Here, we call null.setInput, which takes the number of the input on the node, as well as the node to connect to it.
Prompt: The output nulls aren't laid out nicely, so read through the docs page for hou.Node and see you can find a function to add to the loop that will move a node to a good position.
Extra Info
hou.Node vs hou.OpNode
Since Houdini 20.0, hou.Node has been further split up into sub-classes. This is due to the fact that different options may be available depending on whether a node is a sop node, obj node, etc. Most of the stuff exists on hou.Node, but if you can't find info you're looking for, it is worth checking out the specific node page for the node you are working on.
List vs Tuple
For the case above, the only real difference between the list and the tuple is that you won't be able to directly modify the tuple, and should rather recreate it as a list (with list()) if you need to mess with it.
If you did the prompt for Day 3, you may have found node.moveToGoodPosition(), here's what I used:
def create_output_null():
nodes = hou.selectedNodes() # We get our selected items
for node in nodes:
new_name = "OUT_" + node.name()
output = node.createOutputNode("null", node_name=new_name)
output.moveToGoodPosition()Lets's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes.
Parameters
If we assume we have our node stored as node in a script, we can get a parameter by doing node.parm("parm_name"). Here is the docs page for node.parm() and if you click on it, you will see "-> hou.Parm". This shows what the function returns, and its worth clicking through to hou.Parm and seeing all the useful stuff there is to learn.
Create a Transform Sop and select it. A fundamental thing to understand with getting a parameter, is that we get the hou.Parm back, and from there, we can get its value, get its value, etc.
Create a function in TDPUtils.py called get_parms and make a shelf tool that calls it.
Now, let's loop through all selected nodes (this is a good thing to use, even if you only need one node, as it allows you to adapt it to work for multiple nodes if needed). A node like Transform that has a vector parameter, with multiple values, is still technically 3 parameters under the hood. Mousing over the label will reveal: Parameters: tx ty tz. In this case, let's just work on tx
import hou
def get_parms():
for node in hou.selectedNodes():
our_parm = node.parm("tx")
print(our_parm)If we run the script with the transform selected, it will print: <hou.Parm tx in /obj/geo1/transform2>. As we know, this is a hou.Parm, and if we want to get the value, we can change our script:
import hou
def get_parms():
for node in hou.selectedNodes():
our_parm = node.parm("tx")
value = our_parm.eval()
print(value)We use eval() to evaluate the parameter. This will read the value at the current frame, and evaluate any expressions we have set for the parameter ($FF for example).
We can also set a parameter just as easily:
import hou
def get_parms():
for node in hou.selectedNodes():
our_parm = node.parm("tx")
value = our_parm.eval()
our_parm.set(value*2)In this case, our_parm is just a reference to node.parm("tx"), so we can call the .set function on it, to set the parameter to whatever we pass as the argument.
Parameter Expressions
Now that we have set a parameter, we also set the expression, just as we could do when typing in the parameter box. Let's take the tx parameter, and set it to ty and multiply it by 2.
In this case, we don't want to set it to the value of ty, but specifically set it as a reference to ty. There are other hou.Parm methods we can use, but for the sake of learning, we will be doing it manually.
We will need to create 2 variables, one being our tx parameter, the other being our ty parameter:
import hou
def get_parms():
for node in hou.selectedNodes():
tx = node.parm("tx")
ty = node.parm("ty")Now, if we think about how this would be written manually in the tx box, it would be: ch("ty")*2 (This is a crude example as the paths are on the same node, but we will expand on it later).
If we read the docs page for parm.setExpression, we can see the only required argument is a string that is the expression, and we will build that expression in our script. What we need is the path of the parameter.
import hou
def get_parms():
for node in hou.selectedNodes():
tx = node.parm("tx")
ty = node.parm("ty")
ty_path = ty.path()
print(ty_path)In my case, I get /obj/geo1/transform1/ty which is the absolute path of the parameter. For now, we will use this to construct our reference (some fun in Extra Info). Let's add to our script to build the reference:
import hou
def get_parms():
for node in hou.selectedNodes():
tx = node.parm("tx")
ty = node.parm("ty")
ty_path = ty.path()
ref_string = 'ch("' + ty_path + '") * 2'
print(ref_string)If we run this, it prints ch("/obj/geo1/transform1/ty") * 2, which is just what we need. The last step is to set the expression on the parm:
import hou
def get_parms():
for node in hou.selectedNodes():
tx = node.parm("tx")
ty = node.parm("ty")
ty_path = ty.path()
ref_string = 'ch("' + ty_path + '") * 2'
tx.setExpression(ref_string)Congratulations, you have set a parameter expression!
Prompt: Create a workflow script for yourself that involves creating a node and setting a parameter value/expression.
Extra Info
hou.Parm has some really useful methods, such as parm.node() which returns the path of the node the parameter exists on. We can use this to run a script using the parameter we right click on, or we can use this to change our absolute path above to a relative one.
Here is the same script, but we use node.relativePathTo() to get the path required, and we construct the string using f-strings:
import hou
def get_parms():
for node in hou.selectedNodes():
tx = node.parm("tx")
ty = node.parm("ty")
start_node = tx.node()
start_name = tx.name()
end_node = ty.node()
end_name = ty.name()
rel_path = start_node.relativePathTo(end_node)
ref_string = f'ch("{rel_path}/{end_name}") * 2'
tx.setExpression(ref_string)Lets's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes.
The UI Module
This is such a fun one, this is where you really start to feel like you're making some real tools! For this one, let's work alongside the docs page for hou.ui. At the start of the page, you will see "Pane Layout", we do not even need to worry about this yet, and will wrap around to it later in the series.
Let's scroll down to the "Scripted UI" section. Now is a good time to start a new python file i our scripts folder, I will call it TDPui.py. In here, let's make a new function called set_node_color:
import hou
def set_node_color():
nodes = hou.selectedNodes()
for n in nodes:
passSo, now that we are looping through our selected nodes, we could look through hou.OpNode and find node.color() which gives us the nodes color, and node.setColor(color), which will set our color. If you are reading the docs, you will see the former returns a hou.Color and the latter accepts a hou.Color. If we run to the docs page for hou.Color, we can see there are a lot of helpful functions, but also an example for creating a color. We will implement that into our script:
import hou
def set_node_color():
nodes = hou.selectedNodes()
new_col = hou.Color((1.0, 0.0, 0.1)) # accepts a tuple of floats, so we pass it that
for n in nodes:
n.setColor(new_col)If we run this in a shelf tool, it is hardly exciting, we can change the color of our nodes to red, but now we can play with that scripted UI from before. Let's take a look at the selectColor() function. We can see it takes an optional argument of inital_color, so we can leave that out, and it returns a hou.Color, just what we need!
Let's adapt our script:
import hou
def set_node_color():
nodes = hou.selectedNodes()
new_col = hou.ui.selectColor()
for n in nodes:
n.setColor(new_col)If we run this, we get a popup to choose our color, and when we apply it, we get our nodes in the color we chose! This is getting fun, right!
So this is cool, but its not as interactive. Sometimes the colors don't look as nice as we had hoped, and opening it over and over to dial in is not ideal. Now we can use the more advanced openColorEditor function to fix this.
If we look at the function, its arguments are as follows:
openColorEditor(color_change_callback, include_alpha=False, initial_color=None, initial_alpha=1.0)Let's simplify it a bit, we don't need alpha, we won't set an initial color or alpha, so really all we need is this magical color_change_callback. Simply, a callback is another function, and in this case, it will run every time we change the color in the editor, rather than we click "Ok".
Let's adapt our script as follows:
import hou
def set_node_color(color, alpha):
nodes = hou.selectedNodes()
for n in nodes:
n.setColor(color)
def open_color_editor():
hou.ui.openColorEditor(set_node_color, include_alpha=False)Notice we changed the function names, so ensure to update this in your shelf tool. When we run this, it now runs the set_node_color every time we adjust the color in the editor!
This works great, now let's explore another option, readInput.
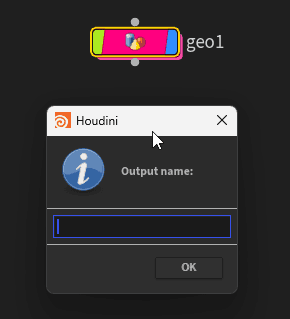
If we look at the docs, while a bit of a mess, we can see at the end, it will return a tuple of an int, and then a string. With these more involved scripted ui, we may need to know which button the user pressed (Apply, Accept, Cancel, etc), as well as any values they type in. In this case, it's simply a number for which button, and the input of our text box.
Let's go back to our TDPUtils.py and adapt our create_output_null function as follows:
def create_output_null():
node = hou.selectedNodes()[0] # we are only getting the first node
idx, name = hou.ui.readInput("Output name:")
new_name = "OUT_" + name
parent = node.parent() # get the parent node
null = parent.createNode("null", node_name=new_name)
null.setInput(0, node)Here, in the third line, we use idx, name = hou.ui.readInput("Output name:"), because as we saw, the function is returning those 2 things in that order.
Now when we run this, we get a pop up to write the name we want to use, and then it sets the node name. The only issue right now, is if we click the close button on the popup, it still makes the output null, so we need to adapt our function a bit. The docs page shows all of the optional arguments there are:
readInput(message, buttons=('OK',), severity=hou.severityType.Message, default_choice=0, close_choice=-1, help=None, title=None, initial_contents=None)We only really need to take note of the default_choice and close_choice values, these values show what the idx variable will be if the user presses enter, or closes the dialogue box. Knowing that, we can add a condition to our function to work around this:
def create_output_null():
node = hou.selectedNodes()[0] # we are only getting the first node
idx, name = hou.ui.readInput("Output name:")
new_name = "OUT_" + name
parent = node.parent() # get the parent node
if not idx == -1 and not name == "":
null = parent.createNode("null", node_name=new_name)
null.setInput(0, node)Here we added 2 conditions simultaneously, "If we didn't close the window", and "if we didn't leave the box empty".
The scripted UI module has some really useful and fun stuff hidden in it, so I urge you to have a play with some of the more complex bits, as it is all really well documented with examples for almost all of the functions.
Lets's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. we also know how to create UI popups to read data from the user.
Kwargs
Now that you can say with confidence, "I know how to create a script, import it and run it", you may find yourself wondering where else you can launch these scripts from. We will get to that, but the first thing we need to familiarise ourselves with is the concept of kwargs.
Let's create a new function in our TDPUtils.py file, and call it get_kwargs():
def get_kwargs(kwargs):
print(kwargs)You will notice that here we have added a required argument called kwargs. In most cases, anywhere you can run a script from, there will be a dictionary named kwargs. In our shelf tool, we can import TDPUtils and run TDPUtils.get_kwargs(kwargs).
When we run this, we will get this in the console:
{'toolname': 'tool_1', 'panename': '', 'altclick': False, 'ctrlclick': False, 's
hiftclick': False, 'cmdclick': False, 'pane': None, 'viewport': None, 'inputnode
name': '', 'outputindex': -1, 'inputs': [], 'outputnodename': '', 'inputindex':
-1, 'outputs': [], 'branch': False, 'autoplace': False, 'requestnew': False}It's not pretty, but we can see some really useful information here, such as which modifier keys are used, and a lot of empty info too. The level of information here can depend on where you run it from.
Let's modify our function to loop through the dict, and make it a bit easier to read:
def get_kwargs(kwargs):
for k,v in kwargs.items():
print(f"{k}: {v}")Using dict.items() is a common way to get the name of the item, as well as the value into 2 variables that you can print.
Now, let's set up my second most common way of running scripts:
Let's create a simple HDA, just an empty subnet saved as a digital asset (go here if you dont know how to do this).
Let's right click it, and click "Type Properties". This will open a menu, and we can go to the parameters tab, and on the left we can drag a button to the right hand side. We set the name and label for the button, in my case, "execute".
Then, we can jump over to the "Scripts" tab. At the bottom left, there is a dropdown menu called "event Handler". lick that and then click on "Python Module". This created a script on the left called PythonModule, on the right, we can now write a script. As you know by now, I like to keep all scripts on disk, but for this example, let's write a quick function that prints our kwargs. We can copy paste the one we used previously:
def get_kwargs(kwargs):
for k,v in kwargs.items():
print(f"{k}: {v}")We could also directly import and call our TDPUtils function like this:
import TDPUtils
def pass_to_script(kwargs):
TDPUtils.get_kwargs(kwargs)We can put this in the PythonModule section, but now we need to run it from our HDA. Let's jump back to our "Parameters" tab, and click on our button parameter. Here we can click on the "Callback Script" section, and in it, we can write:
hou.phm().get_kwargs(kwargs) # if you just wrote the function
hou.phm().pass_to_script(kwargs) # if you did the second option and ran the function in TDPUtils
If we then click Apply, and Accept, we can then click the button on our HDA, and it will print our kwargs. So, we have now run our script in the PythonModule from the button. We know our get_kwargs function exists in our TDPUtils file, so we can adjust our PythonModule script to import it and run it, but it feels like too many places just to get the code to run.
For this, we can adjust the script that is in the Callback Script, to import and run from there. The caveat is that if we press "Enter" for a new line, it doesn't create it. So, what we can do is this:
Place our cursor in the "Callback Script" box, and press Alt+E, to open it in the expression editor. From here, we can use our line breaks just fine. Write:
import TDPUtils
TDPUtils.get_kwargs(kwargs)When we click Accept, the window closes and the line updates to: import TDPUtils¶TDPUtils.get_kwargs(kwargs) (this character wont copy and paste, don't try to copy it).
The other option is to write the line like this:
import TDPUtils; TDPUtils.get_kwargs(kwargs)Using either method, we can now run our script file straight from the button, without needing the PythonModule, which is nice and clean, and we now have access to our kwargs.
While this seems a bit convaluted, my goal has always been to keep as much code free and usable as easily as possible. This image may make it easier to understand:
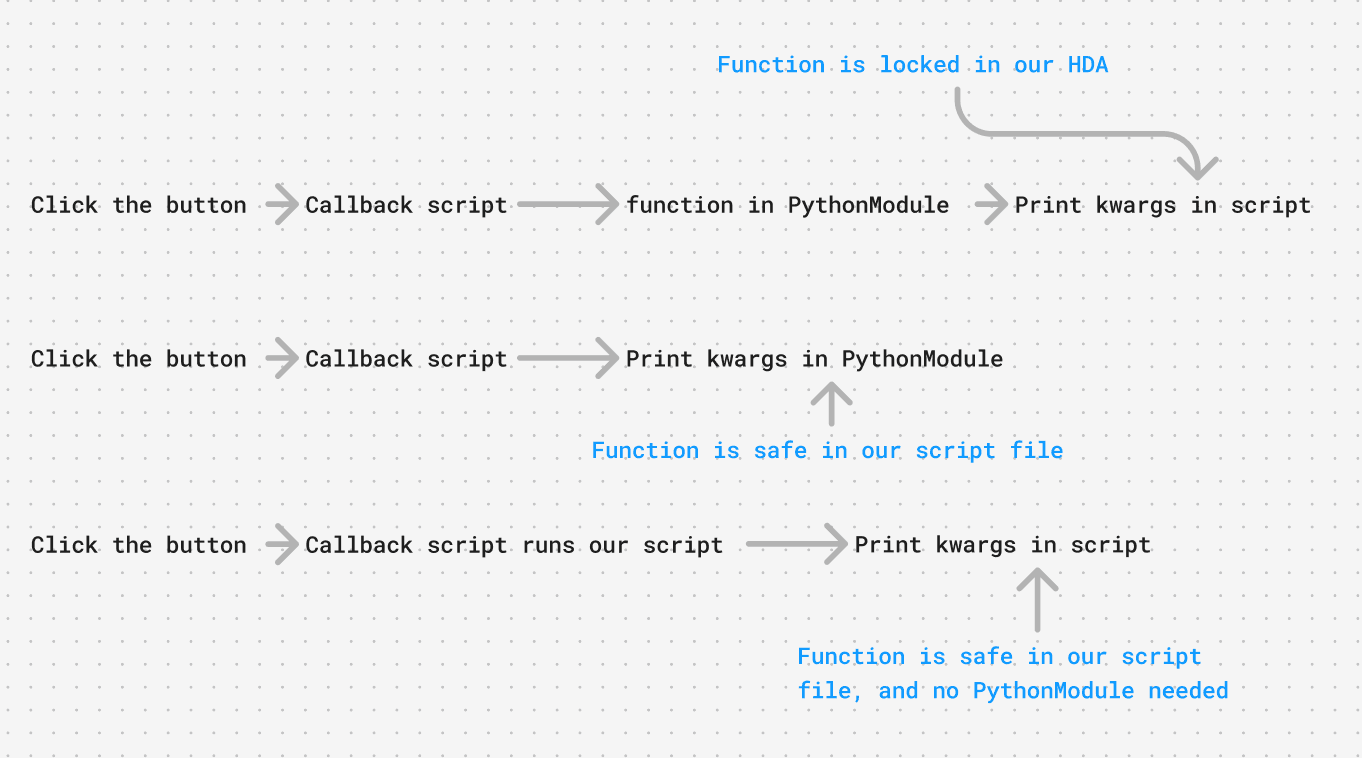
The other events
You can see these events in 2 places: The first being what we saw above, where we selected PythonModule
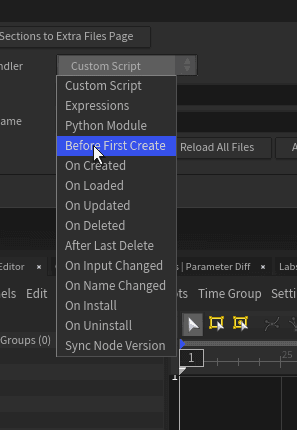
This docs page also lists them with some more detail.
There is not much to say here, but using the principles described above allows us to hook into all of these events and do things, for example using On Created to set the color of our node, or to use On Input Changed to readjust the range on an Attribute Remap inside our HDA.
Day 7 - Menus
flag
Lets's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. We know how to create UI popups to prompt the user for more information. We know how to access the kwargs dict, and use it in our scripts to get specific info related to context we run the script.
Menus
If we look at this docs page, we can see all of the places we can inject tools into the menus throughout Houdini. I will be using OPMenu.xml, which is the menu we see when we right click on a node. I will not be going into the complexities of placement in the menu right now, so just copy and paste this block, and save it as OPMenu.xml in our root TDP folder:
<?xml version="1.0" encoding="UTF-8"?>
<menuDocument>
<menu>
<subMenu id="tdp_menu">
<label>TDP</label>
<scriptItem id="TDP_kwargs">
<label>TDP Get Kwargs</label>
<scriptCode><![CDATA[
import TDPUtils
TDPUtils.get_kwargs(kwargs)
]]> </scriptCode>
</scriptItem>
</subMenu>
</menu>
</menuDocument>You may notice that the formatting here is horrible, sadly this is just how the indentation needs to be for the python scripts to work
Now that we have saved this file, we can click the "Reload Module" shelf tool, and if we right click on a node, we will see a "TDP" menu at the bottom of the list (it may be in a different location for you, but see Extra Info for more).
Here, we created a submenu, and inside that, a scriptItem, which is our single "Get Kwargs" script.
If we run this script, we can see it will print the kwargs again. but this time, very different info comes through:
networkeditor: <hou.NetworkEditor panetab7>
commonparent: True
networkeditorpos: (-1.1045277812617589, 0.7014172892917081)
items: [<hou.SopNode of type box at /obj/geo1/box1>]
node: box1
toolname: h.pane.wsheet.TDP_kwargs
altclick: False
ctrlclick: False
shiftclick: False
cmdclick: FalseTwo very useful things here are that we get node, and we get the networkEditor. We aren't going to use network editor here, just node.
Now that we know our script can take kwargs as an argument and get this info, we can work easily with the node without having to get it through hou.selectedNodes().
This was a simpler way to get the node, but doesn't seem as useful as our next use-case: the parameter menu.
Take our OPMenu.xml and duplicate it. We will rename it to PARMmenu.xml. Adjust the contents as below:
<?xml version="1.0" encoding="UTF-8"?>
<menuDocument>
<menu>
<subMenu id="tdp_menu">
<label>TDP</label>
<scriptItem id="TDP_rand_inp_att">
<label>TDP Randomize Input Attribute</label>
<scriptCode><![CDATA[
import TDPUtils
TDPUtils.randomize_input_attribute(kwargs)
]]> </scriptCode>
</scriptItem>
</subMenu>
</menu>
</menuDocument>We can see here that we now need a function called randomize_input_attribute, but first, lets thing of the logic:
Let's say you've dropped down an Attribute Remap, and want to add some variation to the attribute before we remap it; so what info do we need?
Our current node, our current parameter, and our current parameter value.
Let's create the function and first read the kwargs we get from it:
def randomize_input_attribute(kwargs):
get_kwargs(kwargs)Because we are in the TDPUtils file, we can simply call our other functions in the script and use them there, rather than having to rewrite them. I use this to get the pretty version of our kwargs.
This prints:
parms: (<hou.Parm inname in /obj/geo1/attribremap1>,)
toolname: h.pane.parms.TDP_rand_inp_att
altclick: False
ctrlclick: False
shiftclick: False
cmdclick: FalseYou will see we get parms, which is a tuple of hou.Parm, but only contains our parameter. Using what we learned about hou.Parm, we know we can just use parm.node() to get the node. Let's build out the base of our function:
def randomize_input_attribute(kwargs):
parm = kwargs['parms'][0]
node = parm.node()
att_name = parm.eval()
print(att_name)Now we can right click the "Original Name" in our Attribute Remap, and run our script. It should print our attribute name (make sure you set it).
Using our new connection and creation knowledge, we can make an attribute noise and connect it between our nodes:
def randomize_input_attribute(kwargs):
parm = kwargs['parms'][0]
node = parm.node()
att_name = parm.eval()
current_connection = node.input(0)
noise = node.createInputNode(0, "attribnoise::2.0")
noise.setInput(0, current_connection)Now, all of our connections are made. We had to get the current_connection to reconnect the nodes in order, otherwise the Attribute Noise would have no input. We get the variable before we connect it, otherwise the input changes.
All that is left is to set the parameter to the value we stored, and set the attribute type to "Float"
def randomize_input_attribute(kwargs):
parm = kwargs['parms'][0]
node = parm.node()
att_name = parm.eval()
current_connection = node.input(0)
noise = node.createInputNode(0, "attribnoise::2.0")
noise.setInput(0, current_connection)
noise.parm("attribtype").set("float")
noise.parm("attribs").set(att_name)The attribute type dropdown needs to be set to "float", we can see these options by opening the parameter interface and checking the menu options for the parameter.
This works great, but right now it shows up when we right click any parameter, so we need to add a condition that allows us to control when this script item shows up in the menu. We can do this in the PARMmenu.xml file, using the expression option:
<?xml version="1.0" encoding="UTF-8"?>
<menuDocument>
<menu>
<subMenu id="tdp_menu">
<label>TDP</label>
<scriptItem id="TDP_rand_inp_att">
<label>TDP Randomize Input Attribute</label>
<expression><![CDATA[
import TDPUtils
return TDPUtils.randomize_attribute_condition(kwargs)
]]></expression>
<scriptCode><![CDATA[
import TDPUtils
TDPUtils.randomize_input_attribute(kwargs)
]]> </scriptCode>
</scriptItem>
</subMenu>
</menu>
</menuDocument>As you can see, we need to create a new function (you could also write the small script straight in the menu file, but I don't suggest it). A special note, is that we make our expression return what value the function returns, this is needed for the expression to filter correctly.
Let's add our function, and create an if statement to check if the node and parameter name meet our requirements:
def randomize_attribute_condition(kwargs):
parm = kwargs['parms'][0]
node = parm.node()
node_con = node.type().name() == "attribremap"
parm_con = parm.name() == "inname"
if node_con and parm_con:
return 1
else:
return 0
def randomize_input_attribute(kwargs):
parm = kwargs['parms'][0]
node = parm.node()
att_name = parm.eval()
current_connection = node.input(0)
noise = node.createInputNode(0, "attribnoise::2.0")
noise.setInput(0, current_connection)
noise.parm("attribtype").set("float")
noise.parm("attribs").set(att_name)Here, we create 2 conditions: checking if the node.type().name() is "attribremap", and parm.name() should be "inname", which is the name for the input attribute parameter.
We use if node_con and parm_con to check if both conditions are met. Now, if we reload and our menu script will only show on the parameter we specify.
Now that you've done this, you have know all the steps to create custom menu entries wherever you desire.
Let's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. We know how to create UI popups to prompt the user for more information. We know how to access the kwargs dict, and use it in our scripts to get specific info related to context we run the script.
Attributes
By now, we can use our own discretion as to where to create scripts, but I will always suggest making a file and importing it.
Today will be a bit more theory based than the other days, and will outline some useful ways to work with this data, and prepare us for tomorrows write up.
Let's create a new file called TDPGeo.py, and in it, a function called analyze_geo
import hou
def analyze_geo():
node = hou.selectedItems()[0]
geo = node.geometry()
for pt in geo.iterPoints():
print(pt)If we create a box node, select it and then run this script, the console will print each point in our box. You will see we get hou.Point, and as usual we can dive into the docs for hou.Point, we can see all of the methods available to us.
Now, we can make an attribute noise, I have set my attribute to foo. Let's say we wanted to get the min and max of this attribute similar to how Attribute Remap does, we get our attribute, and first store it in a list:
import hou
def analyze_geo():
node = hou.selectedItems()[0]
geo = node.geometry()
foo_list = []
for pt in geo.iterPoints():
our_att = pt.attribValue("foo")
foo_list.append(our_att)Now if we print foo_list, we get all of the values of our attributes. Now that we have that, we can use the python min and max functions, which let us get those values in relation to a list.
import hou
def analyze_geo():
node = hou.selectedItems()[0]
geo = node.geometry()
foo_list = []
for pt in geo.iterPoints():
our_att = pt.attribValue("foo")
foo_list.append(our_att)
min_v = min(foo_list)
max_v = max(foo_list)
print(f"Min: {min_v}\nMax: {max_v}")Here, we have found the min and max, so if we needed to set a parameter with either of both of these values, we could use the skills we learned in Day 4 to do so.
Python vs Wrangle
Just a quick note on the way that we loop through elements here: If we compare something like a point wrangle, where intrinsically we are running through on each point, when using hou.geometry we have to define these loops ourselves, but as seen with geo.iterPoints, there are already functions defined for us to make this easier. The bottom line is:
Wrangle = runs on each point Python stuff = runs on geometry, define loops yourself.
Now we can try something a bit more complex. Let's say we have a piece of geometry with a few material assignments, and we want to create a split node for each occurrence of a material, so that we have our geometry nice and organized.
import hou
def split_by_materials():
node = hou.selectedItems()[0]
geo = node.geometry()
mat_list = []
for prim in geo.iterPrims():
matname = prim.attribValue("shop_materialpath")Here, we get the attribute just as we did before. The next step is more complex than before, where we just added values to the list, we will need to be smart about filtering them. Do to this, we will use and if statement. We want to loop through each primitive, get the material name, and if its not in the list, we can add it.
import hou
def split_by_materials():
node = hou.selectedItems()[0]
geo = node.geometry()
mat_list = []
for prim in geo.iterPrims():
matname = prim.attribValue("shop_materialpath")
if matname not in mat_list:
mat_list.append(matname)Nice and simple, now we have a list of each material occurrence, so we can use some knowledge from before to create an output node for each of these materials:
import hou
def split_by_materials():
node = hou.selectedItems()[0]
geo = node.geometry()
mat_list = []
for prim in geo.iterPrims():
matname = prim.attribValue("shop_materialpath")
if matname not in mat_list:
mat_list.append(matname)
for mat in mat_list:
split = node.createOutputNode("split")
name = f'@shop_materialpath=="{mat}"'
split.parm("group").set(name)
split.parm("grouptype").set("prims")After we have looped through all of our prims, we can just loop through the list of materials and create the output nodes, and set the group according to our material name.
You could also combine the actions like so:
import hou
def split_by_materials():
node = hou.selectedItems()[0]
geo = node.geometry()
mat_list = []
for prim in geo.iterPrims():
matname = prim.attribValue("shop_materialpath")
if matname not in mat_list:
mat_list.append(matname)
split = node.createOutputNode("split")
name = f'@shop_materialpath=="{matname}"'
split.parm("group").set(name)
split.parm("grouptype").set("prims")Although, this is a more specific use case and our previous one allows us to use that list for a few things afterwards if needed, you may use your own discretion.
Working with hou.Geometry like this is only read only, but tomorrow we will do some write actions with the python sop, so in preparation I urge you to read through the docs for hou.geometry, as well as hou.Point and hou.Prim to familiarize yourself with the concepts we will use.
Prompt: Adapt our above function to read an input from the user, and split based on the attribute provided.
Let's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. We know how to create UI popups to prompt the user for more information. We know how to access the kwargs dict, and use it in our scripts to get specific info related to context we run the script. We know how to add scripts to our menus, and call them from all over. We know how to read data off of our geometry and work with it.
The Python SOP
The python SOP can prove to be a very useful tool, especially when the task at hand is less dependent on geometry operations, and more requiring of some simple/complex parsing or data processing.
While there are already helper SOPs and TOPs that can do things like import a .csv, writing your own can be valuable in controlling the data and the way you use it down to the last moment.
For this example, we will load up a JSON file and create points with attributes for each of they keys.
Drop down a Python SOP, and before we do anything else, open the parameter interface for the node and add a file parameter. I have called mine file. Now we can add to the code of the python sop as follows:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()We get the path of our file parm with .eval() (otherwise we just get the parm), and now we can load the JSON. I have created an example file, so copy this and save it as .json, and then direct the file path to it.
[
{
"Car": "BMW 120i",
"Coolness": "6",
"Realistic": "8",
"Fuel Efficiency": "9",
"Technology": "10",
"Storage": "7",
"Price": "320000"
},
{
"Car": "Ford Ecosport",
"Coolness": "6",
"Realistic": "7",
"Fuel Efficiency": "6",
"Technology": "7",
"Storage": "9",
"Price": "250000"
},
{
"Car": "Mercedes 230 CE",
"Coolness": "10",
"Realistic": "4",
"Fuel Efficiency": "4",
"Technology": "3",
"Storage": "5",
"Price": "200000"
},
{
"Car": "BMW x1 180i",
"Coolness": "7",
"Realistic": "8",
"Fuel Efficiency": "8",
"Technology": "8",
"Storage": "10",
"Price": "300000"
},
{
"Car": "Haval H2",
"Coolness": "5",
"Realistic": "6",
"Fuel Efficiency": "6",
"Technology": "6",
"Storage": "10",
"Price": "225000"
},
{
"Car": "Audi Q3",
"Coolness": "6",
"Realistic": "6",
"Fuel Efficiency": "6",
"Technology": "5",
"Storage": "8",
"Price": "240000"
},
{
"Car": "Mazda CX-5",
"Coolness": "7",
"Realistic": "7",
"Fuel Efficiency": "7",
"Technology": "7",
"Storage": "7",
"Price": "250000"
},
{
"Car": "Haval Jolion",
"Coolness": "4",
"Realistic": "6",
"Fuel Efficiency": "6",
"Technology": "10",
"Storage": "8",
"Price": "295000"
},
{
"Car": "Toyota Rav 4 GX",
"Coolness": "7",
"Realistic": "7",
"Fuel Efficiency": "6",
"Technology": "7",
"Storage": "10",
"Price": "300000"
},
{
"Car": "Jimny AllGrip",
"Coolness": "8",
"Realistic": "5",
"Fuel Efficiency": "6",
"Technology": "6",
"Storage": "7",
"Price": "300000"
}
]Now that we have that saved, we can read the JSON in our python sop:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
print(data)We should now get a console popup with our data. The key thing here, is that its parsed nicely into an array of objects, we we can easily loop through it and create some points. First, let's start with our loop:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
print(index, line)Here, we use enumerate count out spot in the loop. Not needed, but more often than not, it will be useful to have.
The next thing to understand is just a pure python thing, which is that the line we get out will be an object, and with that we need to essentially loop through the key value pairs in the object.
We could see both sides of the object by printing line.keys() or line.values(), but we want both, as we will use the key name to create an attribute, and the value to set it.
Python lets use use line.items() to get both together (I know the namin)
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
for key, value in line.items():
print(key, value)So now, more hand waving and thinking of what we are doing here: The way we are getting each line, we will want to create a point, and then an attribute for each key, but if we already have created an attribute, we know that we don't need to. The simplest way to do this will be to use hou.Geometry.findPointAttrib() which returns None if the attribute doesn't exist.
If we just look at this code quickly to understand it, let's use the example of an attribute called "price":
node = hou.pwd()
geo = node.geometry()
price = geo.findPointAttrib("price")
if price == None:
price = geo.addAttrib(hou.attribType.Point, "price", 0)
print(price)Here, we look for price attribute, and if it ISN'T found, we create it, at the end we print, so regardless of how we find or create it, price at the end always ends with a created attribute. This works, and is fine, but I prefer to do a classic python one liner that feels a bit cleaner:
node = hou.pwd()
geo = node.geometry()
price = geo.findPointAttrib("price") if not geo.findPointAttrib("price") == None else geo.addAttrib(hou.attribType.Point, "price", 0)
print(price)While a bit longer, this inline if statement is very powerful and quick.
Let's get back to our code, using the knowledge above. When we loop through the line we can first create the point:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
# create point
pt = geo.createPoint()Then we can create our attributes:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
# create point
pt = geo.createPoint()
# create attributes
for name in line.keys():
name = name.replace(" ", "_")
att = geo.findPointAttrib(name) if not geo.findPointAttrib(name) == None else geo.addAttrib(hou.attribType.Point, name, 0.0)Unlike vex, with python we need to explicitly create an attribute before we can assign its value, so we loop through all keys (and change all the spaces in the name to _), and do what we learned above. We can imagine the flow of the loop like so:
First line - No attribute found, so we create it. Second line - Attribute found, we just use it.
Now that the attributes are guaranteed to exist, we can simply loop through the items() and set accordingly.
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
# create point
pt = geo.createPoint()
# create attributes
for name in line.keys():
name = name.replace(" ", "_")
att = geo.findPointAttrib(name) if not geo.findPointAttrib(name) == None else geo.addAttrib(hou.attribType.Point, name, 0)
# set attributes
for key, value in line.items():
if not key == "Car":
name = key.replace(" ", "_")
attrib = geo.findPointAttrib(name)
val = int(value)
pt.setAttribValue(name, val)We use val = int(value) here because all of the data from our JSON is read as a string, so we need to convert it.
I have added a condition here to work on all but Car for now. The reason for this is there is one thing we haven't accounted for, which is the class of the attribute. We just need to add 2 conditions in our code, and we can either do it manually, or programmatically (admittedly a bit hacky).
The simple and crude version is:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
# create point
pt = geo.createPoint()
# create attributes
for name in line.keys():
name = name.replace(" ", "_")
if name == "Car":
att = geo.findPointAttrib(name) if not geo.findPointAttrib(name) == None else geo.addAttrib(hou.attribType.Point, name, "")
else:
att = geo.findPointAttrib(name) if not geo.findPointAttrib(name) == None else geo.addAttrib(hou.attribType.Point, name, 0)
# set attributes
for key, value in line.items():
name = key.replace(" ", "_")
attrib = geo.findPointAttrib(name)
if not key == "Car":
val = int(value)
pt.setAttribValue(name, val)
else:
pt.setAttribValue(name, value)and then the more dynamic version:
import json
node = hou.pwd()
geo = node.geometry()
path = node.parm("file").eval()
with open(path, 'r') as json_file:
data = json.load(json_file)
# process data
for index, line in enumerate(data):
# create point
pt = geo.createPoint()
# create attributes
for name in line.keys():
is_string = False
try:
int(line[name])
is_string = False
except:
is_string = True
name = name.replace(" ", "_")
att = geo.findPointAttrib(name) if not geo.findPointAttrib(name) == None else geo.addAttrib(hou.attribType.Point, name, "" if is_string else 0)
# set attributes
for key, value in line.items():
name = key.replace(" ", "_")
attrib = geo.findPointAttrib(name)
type = attrib.dataType() == hou.attribData.String
pt.setAttribValue(name, value if type else int(value))The hacky bit is where we try to parse the name of the car as an int, which will fail in our try-catch block, and we then know if its a number or a string.
So, while rather arbitrary, being able to parse your data dynamically is a very valuable tool for any sort of data ingestion, or if working with visualization of data and you may want or need more control over the way you process it.
Let's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. We know how to create UI popups to prompt the user for more information. We know how to access the kwargs dict, and use it in our scripts to get specific info related to context we run the script. We know how to add scripts to our menus, and call them from all over. We know how to read data off of our geometry and work with it. We know how to parse data from JSON and how to create attributes on our geometry.
Python Panels
While it may seem a bit daunting, Python Panels are simpler that you may think.
Houdini's UI is built mostly off of a Python GUI framework called PyQt/Pyside. It is cross platform, which allows software to work and appear the same. This also benefits us, as Qt is fairly simple to interact with, as well as to build from scratch.
A bit more of a fundamental understanding of what someone may need when using these skills at work: Let's say you create a package with a bunch of utilities and actions, and certain users at work do not want certain behaviors, or just general settings you want to turn off.
The simplest way would be to store a JSON file with preferences that can be loaded on startup, and checked on in our functions when we call them, but your duty as the techy person is to make these things easy to control, so a preferences pane is ideal.
Where do they live?
Python panels are essentially a script that creates the UI, and while they can be shown in different places (normal panes, popups, node parameters), but they are all created in the same way.
Let's create a new script called TDPPrefs.py and in it, you can copy paste this boilerplate:
import hou
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()So, let's do a bit of analysis:
Qt objects are called widgets. From what we know in Houdini, every button, slider, dropdown is a widget, but also, the panel they live on is a widget. Let's take a look at this image to better understand it.
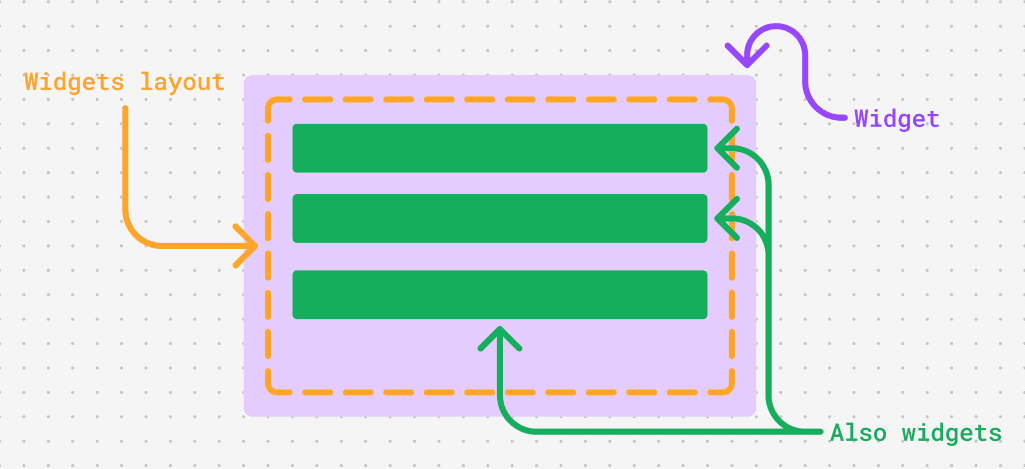
The structure is pretty much generic in all cases: A widget has a layout, and a layout can have any number of child widgets, etc.
So in our code, creating a window isn't as simple as the other popups and just calling hou.ui.readInput, we need to actually create what the input is, in this case.
The short answer, is that the window is QWidget, but this is a class, so we can't modify it directly (think about editing the main "Box" node instead of being able to set parameters on it).
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)We are essentially saying "This is prefpanel, and its a copy of a QtWidgets.QWidget", and this is pretty much the boilerplate for creating the class. Now that we have that, we create a layout for this widget (this widget being the prefpanel), and assign it with self.setLayout.
There is a bunch of self. in this stuff, it basically means that all we are doing is operating on elements that belong to this panel (we could be making 100 panels in our script, but they know what belongs to themselves). ie. self.layout is a variable called layout that belongs to this class.
Okay, picking up the pace a bit:
The widget needs a layout, we create that with self.layout = QtWidgets.QVBoxLayout() The widget needs to have a layout set, we do that with self.setLayout(self.layout) Now, the widget needs to have a parent, even if its a floating window. In this case, we want to use the main Houdini window as a parent, so we use hou.ui.mainQtWindow to get that window, and we pass it the main window, as well as QtCore.Qt.Window, which is a flag to say that it must be a window (as opposed to all the other things widgets could be).
There is a ton of theory to learn and read about, but I will be outlining a more practical way to do it, as sometimes the learn by doing can be the most profitable.
Now, we can create a shelf tool, and in the script we can write:
import TDPPrefs
TDPPrefs.show_panel()If all went well you should have a small blank window.
The first thing anyone wants to do is use a button, so lets add one:
import hou
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.accept_button = QtWidgets.QPushButton('Accept')
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()We create our button, and add it to the layout, but right now clicking it does nothing. Qt uses a system called signals, where the default QPushButton class will emit a signal when clicked. This signal is aptly named "clicked", and we can connect a function to it easily:
import hou
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Notice that we connect it to a function called do_accept that doesn't exist yet, so we will add it. Because we are using classes, we use self.do_accept, and it needs to be a function that belongs to the class. We do this by indenting it one block so that it lives under the class:
import hou
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
print("Accept button clicked")
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()A function in a class is technically called a "method", and will always take a first argument of self, which again is just to signify its ownership by the main class.
When we reload and click the button now, we get a print line saying "Accept button clicked". Nice, so now we have a function that handles our accept button, and we can start applying some of those preference options I spoke about.
We will add a checkbox in just a second, but first let's think about what we need:
We want to store some data in a safe place on disk, related to our preferences. We need to load this data, propagate our preferences dialogue. Save our new options when we press accept.
So, we should have our preference file in a nice location that is user specific. Most programs use the documents folder, but we might as well stick it into the Houdini prefs folder to keep it cleaner. The great part about this is that the Houdini user preferences directory exists as an environment variable already (This is your houdini20.5 etc. folder that we all use to install things).
Let's save a JSON file there called tdp_options.json, and paste this into the contents:
{
"enabled": true
}Now you can save this, and go back to our code. We can construct a function to load our preferences. This is a good function to have exposed globally, so we will not make it part of our class:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
print("Accept button clicked")
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Here, we use hou.text.expandString to get the value of the environment variable, and then we use os.path.join to join the paths in a clean way that respects the separator depending on OS.
I have also added it to the top of our class, so that we load self.prefs with the values. Now, we can create a checkbox and set the state according to the value. First, we create the checkbox, and in our options we defined it as "checkbox" with the keys "label" and "state", so we can do as follows:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
# create checkbox
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.layout.addWidget(self.checkbox)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
print("Accept button clicked")
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()We create the checkbox, and we set the state based off of our preferences.
The next step is to connect a function to the state of our checkbox. If we look at the docs for QCheckBox, we can see signal is called stateChanged.
This is a good time to introduce a concept needed for programmatic UI and function linking.
If we stop for a second and consider a situation where we have 10 checkboxes: Would we want to create a method for each of them that handles each ones check state? No, we would want to create a simple function that can handle any state changes and set the right setting appropriately.
Let's create that function:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(self.handle_checkbox)
self.layout.addWidget(self.checkbox)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
print("Accept button clicked")
def handle_checkbox(self):
print("Checkbox changed")
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Now, we have a function that will print every time the checkbox is changed, but how do we know the state? Well, the docs have it, but its hidden right at the bottom. Essentially, the signal emits with an argument that is the state of the checkbox, and we can catch that in our function by adapting the arguments to def handle_checkbox(self, state). Let's take a look at all the code:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(self.handle_checkbox)
self.layout.addWidget(self.checkbox)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
print("Accept button clicked")
def handle_checkbox(self, state):
print(state)
print("Checkbox changed")
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()The print statement will print 0 or 2 depending on the state, there is a reason for this, but it is not important in this case.
So, with this, we can see we know the state, but if we had 10 checkboxes, how do we know which preference option to update? We could pass it as an argument to our handle_checkbox function but, the connect function doesn't allow us to use arguments. if we change it to self.checkbox.stateChanged.connect(self.handle_checkbox(state, "enabled")), we need to catch that state from the signal somehow. This is where the magic of a lambda function comes in. This is essentially an inline function that let's us create and use it, all in one spot.
The signal emits 1 argument, so our lambda function needs to be:
lambda state: self.handle_checkbox(state, "enabled")This will capture our state from the signal, and allow us to connect it to the handle_checkbox function easily, as well as allowing us to add the "enabled" string to our arguments, so we get it in our function:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(lambda state: self.handle_checkbox(state, "enabled"))
self.layout.addWidget(self.checkbox)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
print("Accept button clicked")
def handle_checkbox(self, state, key):
print(state)
print(key)
print("Checkbox changed")
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Now, we can adapt the handle_checkbox to set our class's self.prefs dict based on the value. I will use a quick inline if statement to make sure we are always setting it as a bool:
def handle_checkbox(self, state, key):
self.prefs[key] = False if state == 0 else TrueNow all we need is a saving function and we can safely adjust our settings as we work:
def save_prefs(prefs):
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
with open(path, 'w') as f:
json.dump(prefs, f)
Again, this function stays out of our class so that we can reuse it in other scripts if needed later.
Now we can adjust our accept button function to save the prefs:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(lambda state: self.handle_checkbox(state, "enabled"))
self.layout.addWidget(self.checkbox)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
save_prefs(self.prefs)
self.close()
def handle_checkbox(self, state, key):
self.prefs[key] = False if state == 0 else True
def save_prefs(prefs):
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
with open(path, 'w') as f:
json.dump(prefs, f)
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Now we can save our prefs and when we reopen the window, the values have persisted!
Also, while we made an arbitrary setting, we could use that value in other scripts like so:
import TDPPrefs
prefs = TPDPrefs.load_prefs()
if prefs['enabled']:
# do things if the option is enabledMore fun
Python panels are a hugely powerful thing, and can really level up the way you interact with your tools.
One of the things we haven't gone over yet, is that Houdini has some prebuilt helper functions that are based of other QtWidgets that we can use as normal, but also can take some extra arguments that allow them to perform as normal Houdini UI elements.
For example, with the native QtWidgets, setting up an element similar to a file picker is a lot of work, we need to define a horizontal layout just for the elements, then add a label, a path preview, and a button to open the file picker, then handle the file picking, update the path preview. These are a lot of steps for something that seems so simple. This is where we can look at hou.qt and see all of the lovely stuff available to us. In this example, I will use the hou.qt.FileLineEdit.
Let's add a file picker to our preferences panel:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(lambda state: self.handle_checkbox(state, "enabled"))
self.layout.addWidget(self.checkbox)
# add our file picker
self.file_path = hou.qt.FileLineEdit()
self.layout.addWidget(self.file_path)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
save_prefs(self.prefs)
self.close()
def handle_checkbox(self, state, key):
self.prefs[key] = False if state == 0 else True
def save_prefs(prefs):
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
with open(path, 'w') as f:
json.dump(prefs, f)
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()This works great out of the box, but it doesn't do anything. We can read the docs page for it and see that it says "This is a specialization of QLineEdit and inherits all signals, slots and methods from that widget." So, we can go to the docs page for QLineEdit and look at the signals here.
We can see textChanged, and this happens when we select a new file, so we can connect that signal to a function, for example to store that path in our prefs. First, let's add a placeholder string to our prefs:
{
"enabled": false,
"file_path": "path/to/file"
}Now we can add a method to our panel that handles string updates:
def handle_string(self, string, key):
self.prefs[key] = stringThen we can make our picker load the path from prefs, and set the prefs again when we update the path:
self.file_path = hou.qt.FileLineEdit()
self.file_path.setText(self.prefs['file_path'])
self.file_path.textChanged.connect(lambda string: self.handle_string(string, "file_path"))
self.layout.addWidget(self.file_path)Let's look at our whole code:
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(lambda state: self.handle_checkbox(state, "enabled"))
self.layout.addWidget(self.checkbox)
self.file_path = hou.qt.FileLineEdit()
self.file_path.setText(self.prefs['file_path'])
self.file_path.textChanged.connect(lambda string: self.handle_string(string, "file_path"))
self.layout.addWidget(self.file_path)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
save_prefs(self.prefs)
self.close()
def handle_string(self, string, key):
self.prefs[key] = string
def handle_checkbox(self, state, key):
self.prefs[key] = False if state == 0 else True
def save_prefs(prefs):
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
with open(path, 'w') as f:
json.dump(prefs, f)
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Everything works perfectly, except we forgot one part: We need to set our window title.
On our class we can use self.setWindowTitle():
import hou
import os
import json
from PySide2 import QtCore, QtWidgets
from PySide2.QtWidgets import QGridLayout
# declare our panel class
class prefpanel(QtWidgets.QWidget):
def __init__(self, parent=None):
super(prefpanel, self).__init__(parent)
self.prefs = load_prefs()
self.layout = QtWidgets.QVBoxLayout()
self.setLayout(self.layout)
self.checkbox = QtWidgets.QCheckBox("Enable")
self.checkbox.setChecked(self.prefs['enabled'])
self.checkbox.stateChanged.connect(lambda state: self.handle_checkbox(state, "enabled"))
self.layout.addWidget(self.checkbox)
self.file_path = hou.qt.FileLineEdit()
self.file_path.setText(self.prefs['file_path'])
self.file_path.textChanged.connect(lambda string: self.handle_string(string, "file_path"))
self.layout.addWidget(self.file_path)
self.accept_button = QtWidgets.QPushButton('Accept')
self.accept_button.clicked.connect(self.do_accept)
self.layout.addWidget(self.accept_button)
self.setWindowTitle('TDP Preferences')
self.setParent(hou.ui.mainQtWindow(), QtCore.Qt.Window)
def do_accept(self):
save_prefs(self.prefs)
self.close()
def handle_string(self, string, key):
self.prefs[key] = string
def handle_checkbox(self, state, key):
self.prefs[key] = False if state == 0 else True
def save_prefs(prefs):
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
with open(path, 'w') as f:
json.dump(prefs, f)
def load_prefs():
path = hou.text.expandString('$HOUDINI_USER_PREF_DIR')
path = os.path.join(path, 'tdp_options.json')
print(path)
with open(path, 'r') as f:
prefs = json.load(f)
return prefs
# function to show the panel
def show_panel():
panel = prefpanel()
panel.show()Now we are truly done. The rest is all about checking the docs and planning simple and clean ways to handle your interaction. You can also read Python Panels for more information, where I go over the other ways to build layouts, and how to get them to show up as panes in Houdini.
Let's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. We know how to create UI popups to prompt the user for more information. We know how to access the kwargs dict, and use it in our scripts to get specific info related to context we run the script. We know how to add scripts to our menus, and call them from all over. We know how to read data off of our geometry and work with it. We know how to parse data from JSON and how to create attributes on our geometry. We know how to create a python panel and propagate it's data from a JSON file.
Working with ramps
Ramps can be a very powerful tool when you start to use float ramps in vex for procedural animation, but you can easily run into a problem of how to store them. We will learn how to break down a ramp into its components, to save it to disk and rebuild when needed.
Let's first create an attribute remap in our scene, and then create a new python script. For this example, I want to place it in the parameter right click, just like how we did in Day 7. You should know how to do this, but here is the code I used:
ParmMenu.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml version="1.0" encoding="UTF-8"?>
<menuDocument>
<menu>
<subMenu id="tdp_menu">
<label>TDP</label>
<scriptItem id="TDP_ramp_save">
<label>TDP Save Ramp</label>
<expression><![CDATA[
import TDPRamps
return TDPRamps.ramp_filter(kwargs)
]]> </expression>
<scriptCode><![CDATA[
import TDPRamps
TDPRamps.ramp_save(kwargs)
]]> </scriptCode>
</scriptItem>
</subMenu>
</menu>
</menuDocument>You can see we need to have 2 functions defined, the ramp_filter that checks if we should show the menu item for this parm, and the ramp_save to actually save the ramp. Let's set up the filter and a placeholder for the saving in `TDPramps.py.
import hou
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
passWe use parm.parmTemplate() to check if its a ramp parameter.
Now we can get into the saving. In Houdini 20.5 they introduced some new functions to get the ramp data, so we will use these. If we scroll right to the bottom of hou.Parm, we can see rampPointsAsData(), so let's first print that in our save function.
import hou
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramp_data = parm.rampPointsAsData()
print(ramp_data)The default linear ramp of the Attribute Remap will give us something like this:
[{'pos': 0.0, 'value': 0.0, 'interp': 'linear'}, {'pos': 1.0, 'value': 1.0, 'interp': 'linear'}]If we look at this, we can see its an array of dict's where each dict represents each point of the ramp.
The point of this script is to save the ramp, so let's add to our function to save the ramp. The one issue is that right now we don't have a name for the ramp, so we can add a popup to use readInput and get a name:
import hou
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramp_data = parm.rampPointsAsData()
idx, name = hou.ui.readInput("Ramp Name", title="Save Ramp")
if name == "":
return
newdata = {
"name": name,
"data": ramp_data
}Now, we need to create a ramps folder in our TDP folder to save these into. Once we make that, we can add to our function to generate a random string for the name, and save the data as json:
import os
import string
import hou
import json
import random
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramp_data = parm.rampPointsAsData()
idx, name = hou.ui.readInput("Ramp Name", title="Save Ramp")
if name == "":
return
newdata = {
"name": name,
"data": ramp_data
}
ramp_id = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(10))
ramp_path = hou.text.expandString("$TDP")
fullpath = os.path.join(ramp_path, "ramps", ramp_id + ".json")
with open(fullpath, "w") as f:
json.dump(newdata, f)That will save our ramp to disk, and the file looks like this:
{
"name": "linear",
"data": [
{ "pos": 0.0, "value": 0.0, "interp": "linear" },
{ "pos": 1.0, "value": 1.0, "interp": "linear" }
]
}Now we can create a load_ramp function, but we should also create a simple ui for this. We can use hou.ui.selectFromList() for this. Because we may want to create a panel that loads these ramps, its a good idea to create a helper function that loads all of the ramps in the folder, that way we can separate the loading and the applying of the ramp into two things.
First, lets make the loader. We can add that to our ParmMenu.xml first:
<?xml version="1.0" encoding="UTF-8"?>
<menuDocument>
<menu>
<subMenu id="tdp_menu">
<label>TDP</label>
<scriptItem id="TDP_ramp_save">
<label>TDP Save Ramp</label>
<expression><![CDATA[
import TDPRamps
return TDPRamps.ramp_filter(kwargs)
]]> </expression>
<scriptCode><![CDATA[
import TDPRamps
TDPRamps.ramp_save(kwargs)
]]> </scriptCode>
</scriptItem>
<scriptItem id="TDP_ramp_load">
<label>TDP Load Ramp</label>
<expression><![CDATA[
import TDPRamps
return TDPRamps.ramp_filter(kwargs)
]]> </expression>
<scriptCode><![CDATA[
import TDPRamps
TDPRamps.ramp_load(kwargs)
]]> </scriptCode>
</scriptItem>
</subMenu>
</menu>
</menuDocument>and then we can load them in our script:
import os
import string
import hou
import json
import random
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramp_data = parm.rampPointsAsData()
idx, name = hou.ui.readInput("Ramp Name", title="Save Ramp")
if name == "":
return
newdata = {
"name": name,
"data": ramp_data
}
ramp_id = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(10))
ramp_path = hou.text.expandString("$TDP")
fullpath = os.path.join(ramp_path, "ramps", ramp_id + ".json")
with open(fullpath, "w") as f:
json.dump(newdata, f)
def load_ramp_folder():
ramp_path = hou.text.expandString("$TDP")
ramp_folder = os.path.join(ramp_path, "ramps")
ramp_files = os.listdir(ramp_folder)
def ramp_load(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
load_ramp_folder()Here we have defined our ramp_load that calls our load_ramp_folder function. In our loading of the folder, we get the path and then all the files in the folder. We can now loop through them and construct an array of all of them:
import os
import string
import hou
import json
import random
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramp_data = parm.rampPointsAsData()
idx, name = hou.ui.readInput("Ramp Name", title="Save Ramp")
if name == "":
return
newdata = {
"name": name,
"data": ramp_data
}
ramp_id = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(10))
ramp_path = hou.text.expandString("$TDP")
fullpath = os.path.join(ramp_path, "ramps", ramp_id + ".json")
with open(fullpath, "w") as f:
json.dump(newdata, f)
def load_ramp_folder():
ramp_path = hou.text.expandString("$TDP")
ramp_folder = os.path.join(ramp_path, "ramps")
ramp_files = os.listdir(ramp_folder)
ramp_files = [f for f in ramp_files if f.endswith(".json")] # filter only json files, just in case
loaded = []
for f in ramp_files:
with open(os.path.join(ramp_folder, f), "r") as file:
data = json.load(file)
loaded.append(data)
return loaded
def ramp_load(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramps = load_ramp_folder()Now, using some nice python list comprehension, we can use just the names to create our selectFromList. This list will return an index of our selection, which we can then use to pull the data from our ramps array at that index, and then use parm.setRampPointsFromData() to set the ramp.
The first step is to load just the ramp names into an array. We can do this with:
ramps = load_ramp_folder()
names = [r["name"] for r in ramps]Then we can can construct our list for selection, and catch the index of the selection and use it to get the data out:
import os
import string
import hou
import json
import random
def ramp_filter(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
return parm.parmTemplate().type().name() == 'Ramp'
def ramp_save(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramp_data = parm.rampPointsAsData()
idx, name = hou.ui.readInput("Ramp Name", title="Save Ramp")
if name == "":
return
newdata = {
"name": name,
"data": ramp_data
}
ramp_id = ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(10))
ramp_path = hou.text.expandString("$TDP")
fullpath = os.path.join(ramp_path, "ramps", ramp_id + ".json")
with open(fullpath, "w") as f:
json.dump(newdata, f)
def load_ramp_folder():
ramp_path = hou.text.expandString("$TDP")
ramp_folder = os.path.join(ramp_path, "ramps")
ramp_files = os.listdir(ramp_folder)
ramp_files = [f for f in ramp_files if f.endswith(".json")] # filter only json files, just in case
loaded = []
for f in ramp_files:
with open(os.path.join(ramp_folder, f), "r") as file:
data = json.load(file)
loaded.append(data)
return loaded
def ramp_load(kwargs):
parm = kwargs["parms"][0]
if parm is None:
return False
ramps = load_ramp_folder()
names = [r["name"] for r in ramps]
sel = hou.ui.selectFromList(names, exclusive=True, title="Select Ramp", column_header="Ramps")[0]
if sel is None:
return
else:
parm.setRampPointsFromData(ramps[sel]["data"])Just like that, we have stored some ramps on disk and we can quickly load our presets from this data.
Let's recap what we know so far:
We know how to create a script and run it in Houdini, how to use arguments in our functions, how to loop through multiple nodes. We know how to create nodes, how to connect them to other nodes. We know how to set parameters, how to set the expressions, and how to get paths of other parameters and nodes. We know how to create UI popups to prompt the user for more information. We know how to access the kwargs dict, and use it in our scripts to get specific info related to context we run the script. We know how to add scripts to our menus, and call them from all over. We know how to read data off of our geometry and work with it. We know how to parse data from JSON and how to create attributes on our geometry. We know how to create a python panel and propagate it's data from a JSON file.
What next
Take a look at the recap above. Look at what you know, you should be proud! You went from nothing to this.
If you made it this far, you might wonder what is next to learn. I had the same though while writing this! The reality is, if you read all of this, and excuse some of my typos, you will probably in a spot where you can start to tackle some of the problems you need to solve.
While this is not an extensive write up with every problem you may have has been outlined, and if my rambling has made any sense, hopefully you have learned a bit of how to think about these things.
So, really Day 12 is the rest of your life. Have fun with it, ask your friends if you can make scripts for them, make a python panel project selector, anything!
I hope you enjoyed it, hopefully next year we can do something bigger and more fun.